I’m going to start by grabbing your attention with this chart from the State of Open Source 2020:
Book a demo today to see GlobalDots is action.
Optimize cloud costs, control spend, and automate for deeper insights and efficiency.

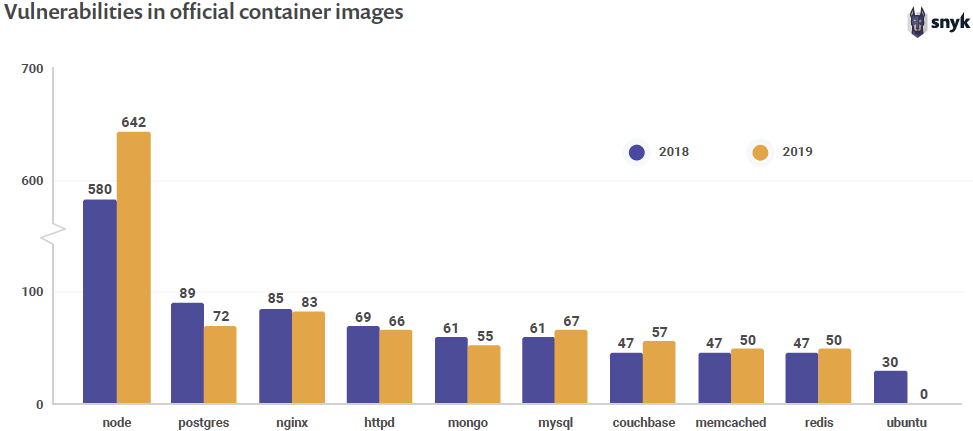
“If you thought pulling the ‘latest’ image kept you safe, you’re wrong”
This chart is showing the number of vulnerabilities in container images. Let’s be clear here, these containers are; vanilla, pristine and pulled fresh from the repositories. So if you thought pulling the ‘latest’ image kept you safe, you’re wrong. It’s worth noting that the node column should actually be 5x taller, the graph has been adjusted for visual purposes. If you were to use node and nginx together that’s 725 vulnerabilities. These are two of the most used containers on the internet today. We are in the middle of a software vulnerability pandemic, and barely anyone is batting an eyelid!
Why are we using open source with known vulnerabilities?
If you worked in IT security and someone came to you with a request to use node, with a side note attached saying it contains 642 known vulnerabilities, what would you say? You’d probably tell them that “it sounds more like a virus than a piece of code to help”, right? The thing is we’ve basically gotten lazy with code, if someone else has written it, then why reinvent the wheel? But just because everyone else is using something and it’s widely distributed, doesn’t make it safe. And by the very nature of open source there’s nobody to point the finger at for this. When Microsoft has a vulnerability it’s all over the news and they have to scrabble to fix it. Who’s accountable for node or nginx? Sure there’s some community that looks after it but typically they’re not paid and it’s on a ‘best efforts’ basis. There’s no pandemonium around open source because there’s essentially nobody to blame.
“It’s actually insane to think you would go onto the internet, pull a random container and merge it into your systems”
Open source should be treated like food
I was first introduced to the concept of ‘software hygiene’ about 5 years ago. The basic premise is that you track all the code you use in your system and at the end you can say it contains x,y,z. It’s something we’re very familiar with in other aspects of our lives, food being the best example. When you goto the supermarket and pick up a product you expect to know; who made it, where it came from, what ingredients were used and what’s the nutritional content. We don’t do this (or at least 72% of us don’t do this, according to the report) for software. Why? It’s actually insane to think you would go onto the internet, pull a random container and merge it into your systems. Would you ever go to the supermarket, pull a random container of food off the shelf and roll the dice that it will be fine? Our attitude towards free software needs to change.
“pulling the ‘slim’ images as opposed to ‘latest’ can sometimes reduce vulnerabilities by 95%”
How can you reduce your risk?
The number one step you can take is to start using software code scanning. Make scans part of your software development life cycle and be rigorous with the process, far too often I’ve seen processes put in place but then ‘ignored’ because they were slowing release cycles. If you don’t need the full image then don’t use it, pulling the ‘slim’ images as opposed to the ‘latest’ can sometimes reduce vulnerabilities by 95%. The world has changed a lot in the last few years and the paradigm of ‘DevSecOps’ has cropped up. If this concept is new to you, then I highly suggest you start googling it quickly so you can bring your organisation up to scratch. Like everything there’s no silver bullet to solve the IT security problems faced by modern organisations. Don’t go it alone, reach out to a technology partner like GlobalDots who can help you navigate those internet storms.


