Picture this scenario:
You’ve just arrived to work on Monday morning (it’s 2020, so by “work” we mean you’ve moved from your bed to your kitchen table). You boot up your computer excited to start working on a new coding project. You just know that this is going to be the thing that impresses your boss and gets you a promotion.
But, just as you open your email, you get a Prometheus alert. You see “high memory usage” and know what this means…your entire day will now be spent on:
Book a demo today to see GlobalDots is action.
Optimize cloud costs, control spend, and automate for deeper insights and efficiency.

- Investigating this bug
- Creating a fix
- Testing and more testing
- And then just maybe pushing a working new version to production

You resign yourself to the task at hand, and finally, after many more cups of coffee and hours of work you’ve solved the problem. At least you think so – it works in the local environment that you’ve created to test it. But, of course, you can’t completely replicate the customer’s environment with their full load.
Your hard-earned fix still has to go through the entire pipeline before it can be deployed in production. Because it’s not even a high priority item, this whole process could take days, with your new project getting pushed to the back burner every time you have to stop and address a new failed test.
What Could be Different:
Sure, the traditional CI/CD pipeline is an improvement over other more manual methods that are less agile. It is also, of course, important to have safeguards in place in order to make sure that one rogue bug doesn’t destroy an entire system. The last thing anyone wants is an unhappy customer.
But, one of the secrets to a happier customer is an effective engineer. Engineers want to write new code and provide new upgrades rather than debugging and testing. The less time they spend on the mind-numbing tasks and the more time they spend coming up with new features, the happier the customer and the greater the company’s bottom line.
Imagine a world in which the scenario above could have gone much differently:
- The high memory usage bug was reported
- Logs and metrics could be added in real-time without creating any downtime
- The cause of the bug could be found quickly and then the fix could be made directly in production
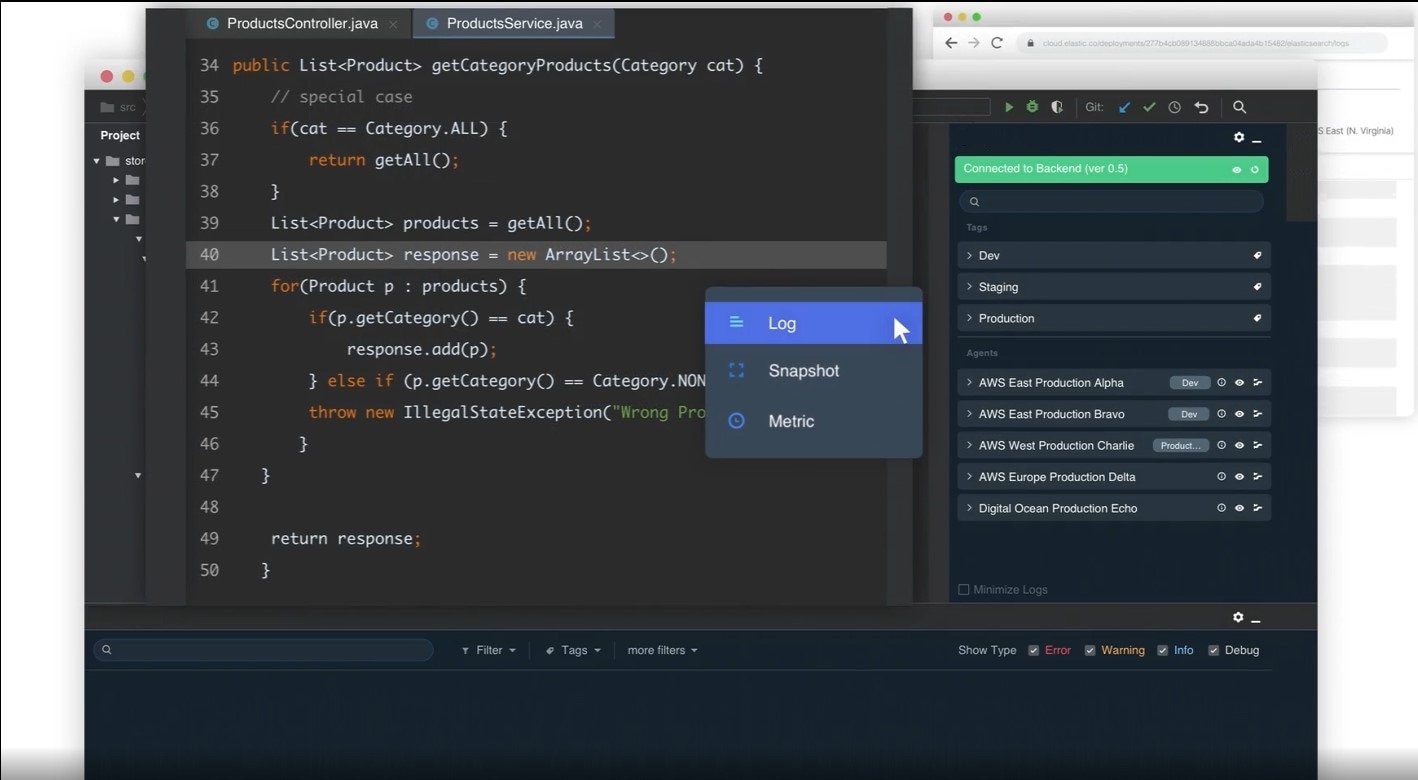
The entire process would have been cut down from days to hours or even minutes. And the engineer in our example above could have gotten that promotion after all!


